Why deploy InfiniBand (IB) when we already have Ethernet?
Cause your AI Factory needs it...

Architecting large-scale GPU clusters, the choice between InfiniBand (IB) and Ethernet isn’t merely about “speed”—it’s a choice between a specialized HPC fabric designed for synchronous orchestration and a commodity data-link layer that has been retrofitted for high-performance workloads.
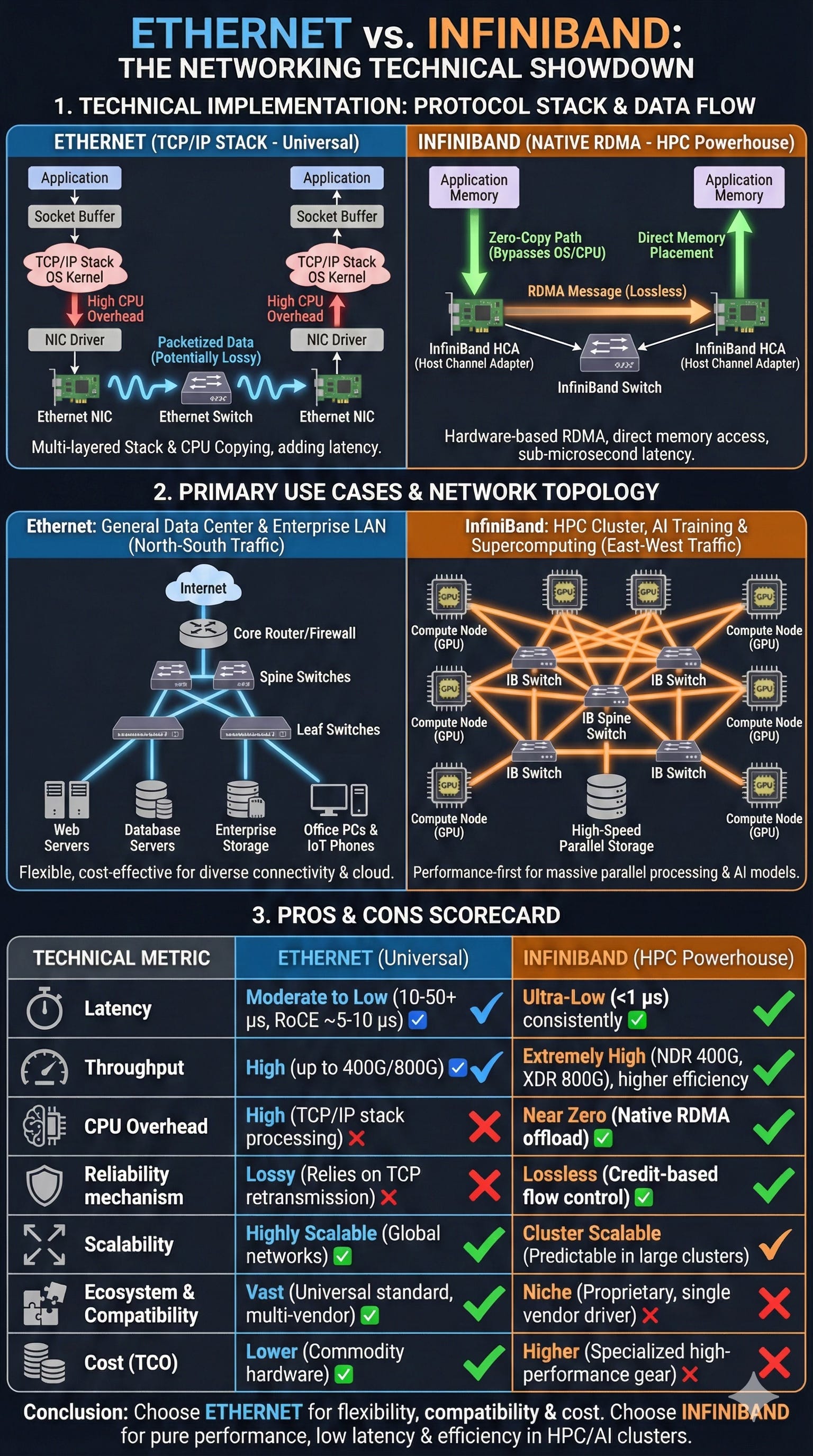
While modern 400G/800G Ethernet (Spectrum-X, RoCEv2) has closed the gap, InfiniBand remains the gold standard for “Scale-Out” architectures in 2025 for the following technical reasons:
The Physics of Losslessness: Credit-Based Flow Control
The most fundamental difference lies in how the fabrics handle congestion.
Ethernet is natively “best-effort.”1 To make it suitable for GPUs (RoCEv2), we use Priority Flow Control (PFC)and Explicit Congestion Notification (ECN). These are reactive mechanisms that can lead to “PFC storms,” head-of-line blocking, and congestion spreading.
InfiniBand uses a Link-Layer Credit-Based Flow Control mechanism. A sender never transmits a packet unless it knows the receiver has the buffer space to hold it. This makes IB a natively lossless fabric without the configuration complexity and “jitter” associated with tuning PFC/ECN on high-radix Ethernet switches.
Tail Latency and Determinism
In distributed training (e.g., LLM pre-training), the workload is typically synchronous, relying on collective operations like All-Reduce.
The “Straggler” Problem: In an All-Reduce operation, the entire GPU cluster waits for the slowest packet.
Fabric Determinism: IB offers significantly lower tail latency (p99). Because it uses a centralized Subnet Manager (SM) to pre-calculate non-blocking, loop-free paths, it avoids the stochastic nature of Ethernet’s distributed MAC learning and ARP broadcasts. In a 2025 NDR (400G) or XDR (800G) environment, IB maintains sub-microsecond switch latencies consistently, whereas Ethernet jitter can spike during “incast” congestion events.
In-Network Computing (SHARP)
InfiniBand is no longer just a “pipe”; it is part of the compute logic. NVIDIA’s Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) offloads collective communications (All-Reduce, All-Gather, Barrier) to the switch silicon itself.
Reduced Traffic: Instead of sending data back and forth between GPUs multiple times, the switches perform the floating-point summation of gradients in-flight.
Efficiency: This reduces the amount of data traversing the fabric by ~2x and frees up GPU cycles that would otherwise be spent on communication overhead. Standard Ethernet ASICs currently lack this deep integration with the AI collective libraries (NCCL/RCCL).
Native RDMA vs. RoCEv2 Overheads
While RoCEv2 (RDMA over Converged Ethernet) provides “Remote Direct Memory Access,” it is essentially an InfiniBand transport header wrapped in UDP/IP/Ethernet frames.
Protocol Overhead: RoCEv2 adds roughly 40-54 bytes of overhead per packet. At 800Gbps, this “encapsulation tax” impacts effective throughput.
Hardware Efficiency: Native IB utilizes Queue Pairs (QP) and a transport layer implemented entirely in hardware (HCA). This results in lower CPU utilization and higher message rates (messages per second) for the small-packet synchronization tasks that dominate AI workloads.
Technical Comparison Summary
You choose InfiniBand when the Job Completion Time (JCT) is your primary KPI and you are scaling beyond ~128 GPUs. At that scale, the “Network is the Computer.” While Ethernet is increasingly viable for inference and smaller-scale tuning (due to lower CapEx and multi-vendor interoperability), InfiniBand’s deterministic nature ensures that your multi-million dollar H100/B200 clusters aren’t sitting idle waiting for a dropped packet to be retransmitted.
To provide a deeper technical analysis, we must move beyond basic “lossless vs. lossy” comparisons and look at the silicon-level implementation of routing, collective offloading, and management planes as they stand today.
Adaptive Routing: Per-Packet Spraying vs. Flow-Level Entropy
One of the most significant performance drivers in InfiniBand (specifically Quantum-2 and Quantum-X800 architectures) is the ability to perform Fine-Grained Adaptive Routing (AR).
InfiniBand: Uses per-packet adaptive routing. The HCA and switches can spray individual packets of a single message across all available paths in a fat-tree topology. Because the fabric is natively lossless and handles reordering in hardware, it achieves near-100% link utilization without the risk of “Elephant Flows” pinning to a single path and causing congestion.
Ethernet (ECMP/RoCEv2): Traditionally relies on Equal-Cost Multi-Path (ECMP), which hashes flows (based on 5-tuple) to specific paths. In AI workloads, where you have a small number of massive “Elephant Flows” (e.g., a 10GB gradient sync), hashing often leads to “collisions” where two heavy flows share a link while others sit idle.
The Gap: While Broadcom’s Tomahawk 5/6 and the Ultra Ethernet Consortium (UEC 1.0) have introduced “Cognitive Routing” and packet-spraying mechanisms, they still require complex NIC-side reassembly and specialized drivers to match IB’s native hardware-level packet distribution.
In-Network Reductions: SHARP vs. Software Collectives
In a large-scale All-Reduce operation, the network is usually the bottleneck. InfiniBand moves the math into the switch using SHARP (Scalable Hierarchical Aggregation and Reduction Protocol).
InfiniBand (SHARP v3): The switch ASIC contains dedicated arithmetic units. When GPUs send gradients for reduction, the switch performs the summation (FP16, BF16, FP32) in-flight. This effectively doubles the fabric bandwidth because data only needs to travel “up” the tree to be reduced, rather than being shuffled across multiple “halves” of a ring or recursive-doubling algorithm in software.
Ethernet: Currently lacks a standardized, multi-vendor equivalent to SHARP. Reductions are handled at the endpoints (GPUs) using NCCL (NVIDIA Collective Communication Library). This consumes GPU memory bandwidth and SM (Streaming Multiprocessor) cycles to manage the communication buffers and state machines.
To analyze the choice between InfiniBand (NDR/XDR) and high-end Ethernet (Spectrum-X/Ultra Ethernet) we must look at the Net Present Value (NPV) of your GPU cluster. For a seasoned pro, the hardware cost is a distraction; the real metric is Goodput-per-Watt and Job Completion Time (JCT).
The Management Plane: Centralized vs. Distribute
The operational stability of a 32,000-GPU cluster is as important as its throughput.
InfiniBand Subnet Manager (SM): IB uses a centralized control plane. The SM has a global view of the entire topology. It pre-calculates the forwarding tables, manages partitions, and handles link failures by immediately pushing updated paths to the switches. This results in deterministic re-convergence times that are often an order of magnitude faster than distributed protocols.
Ethernet (BGP/OSPF): Ethernet uses a distributed control plane. Each switch makes its own routing decisions based on its local view. In a massive scale-out event or a link flap, the time for BGP to re-converge across a high-radix Spine-Leaf can introduce “jitter” and “tail latency” that stalls the entire synchronous training job.
Protocol Overhead and “Goodput”

At 800Gbps (XDR/Tomahawk 6), the protocol “tax” becomes a non-trivial percentage of TCO.
In a multi-petaflop training run lasting weeks, a 5% difference in “Goodput” (actual payload delivered) translates to days of saved compute time on thousands of H100s/B200s.
Impact on Job Completion Time (JCT)
The “Why” of InfiniBand boils down to Predictability.
Lower Tail Latency: By avoiding the stochastic nature of Ethernet’s collision-based flow control and distributed routing, IB keeps the “straggler” GPU to a minimum.
Higher GPU Utilization: Because communication is faster and more efficient (SHARP), the GPUs spend more time in the Compute phase and less time in the Comm phase.
Simpler Tuning: Achieving a “lossless” state in Ethernet (RoCEv2) requires perfectly balanced PFC/ECN watermarks across every switch and NIC in the fabric. InfiniBand is lossless by the laws of its physics (Credit-Based Flow Control), making it much easier to maintain at scale.
To truly contrast these fabrics at the architectural limit, we must look at how the silicon handles the three pillars of distributed AI: Routing Entropy, Collective Congestion, and Protocol Goodput.
As of now (2025), the gap between InfiniBand (NDR/XDR) and Ethernet (Spectrum-X/Tomahawk 6) has narrowed in throughput but diverged in implementation philosophy.
1. Adaptive Routing: Per-Packet Spraying vs. Flow Hashing
In a non-blocking Fat-Tree topology, the goal is to utilize every bit of available bisection bandwidth.
InfiniBand (Quantum-2/X800): Employs Hardware-Level Adaptive Routing. It makes routing decisions on a per-packet basis. Because the IB transport layer handles out-of-order delivery natively in the HCA hardware, switches can “spray” packets of a single RDMA write across all available paths. This results in virtually 100% link utilization regardless of flow size.
Ethernet (Standard/RoCEv2): Traditionally relies on ECMP (Equal-Cost Multi-Path), which hashes based on the 5-tuple. This creates “Elephant Flow” collisions where two 400G flows are hashed to the same 800G link, while another link sits idle.
The 2025 Shift (UEC 1.0): The Ultra Ethernet Consortium (UEC) has introduced “Packet Spraying” for Ethernet, but it requires a specialized Transport Layer (UET) and high-complexity reassembly buffers at the NIC. InfiniBand remains the more mature “spray-and-forget” architecture for seasoned architects who cannot afford the tail-latency spikes caused by ECMP collisions.
Adaptive Routing: XDR vs. Tomahawk 6 (UEC 1.0)
The “Holy Grail” of modern networking is eliminating the “Elephant Flow” problem.
InfiniBand (XDR): Uses Per-Packet Spraying. Because the IB HCA handles reordering in hardware, the fabric can fragment a 10GB gradient and spray it across every available link in the pod. Link utilization stays at >96%.
Ethernet (UEC 1.0): The Ultra Ethernet Consortium (UEC) has introduced Packet Delivery Sub-layer (PDS) to mimic this. However, most legacy Ethernet relies on Entropy-based hashing (ECMP). If two “Elephant Flows” hash to the same physical link, you get a 50% throughput drop on those flows, even if the neighboring link is idle.
Professional Impact: In large-scale training (e.g., Llama 4 pre-training), the synchronous nature of the workload means the entire cluster slows down to the speed of the most congested link. InfiniBand’s deterministic packet spraying eliminates these “micro-bottlenecks.”
2. Tail Latency: The “Noise” of Distributed Control
AI training is a “bulk-synchronous” process. If one packet is delayed (the “straggler”), 32,768 GPUs may sit idle for microseconds, destroying effective TFLOPS.
Deterministic Forwarding: InfiniBand uses a Centralized Subnet Manager (SM). The forwarding tables are computed globally and pushed to the switches. There is no “MAC learning,” no ARP broadcast, and no BGP flapping. This leads to a near-flat latency profile.
The Ethernet Jitter: Ethernet is a Distributed Control Plane. Each switch runs its own spanning tree or BGP process. Under heavy “incast” (many-to-one) scenarios, Ethernet relies on PFC (Priority Flow Control). When a buffer fills, the switch sends a “PAUSE” frame. This can cause head-of-line blocking where unrelated traffic is stalled, leading to the “PFC Storm” phenomenon.
Quantitative Gap: In benchmarks, InfiniBand NDR maintains a p99.9 latency within 2–3x of its base latency. RoCEv2 Ethernet, even with Data Center Quantized Congestion Notification (DCQCN), can see p99.9 spikes of 10–50x during All-To-All operations.
The Management Plane: Determinism vs. Convergence
Seasoned architects know that 10,000-node clusters are “fragile.”
InfiniBand Subnet Manager (SM): IB utilizes a centralized control plane. The SM has a global, real-time map of the topology. If a link flaps, the SM re-calculates the paths globally and updates the linear forwarding tables. Re-convergence is near-instantaneous and deterministic.
Ethernet (BGP/RoCE): Ethernet relies on distributed protocols. When a spine switch fails, BGP must converge across the leaf/spine layers. During this convergence, “black holes” or “micro-loops” can occur, causing RoCEv2 packets to drop. Because RoCEv2 is sensitive to loss, this often triggers a PFC Storm, where the “PAUSE” frames cascade across the fabric, effectively halting the entire training job for milliseconds or seconds.
3. SHARP v3: Why Move Data When You Can Move Math?
The most aggressive differentiator for InfiniBand is In-Network Computing.
NVIDIA SHARP (Scalable Hierarchical Aggregation and Reduction Protocol): Instead of the GPUs doing the math for an All-Reduce (summing gradients), the InfiniBand switch silicons perform the floating-point additions in-flight.
Impact on Throughput: By reducing data at the switch level, SHARP reduces the total amount of data traversing the spine by 50%. Standard Ethernet ASICs (like Broadcom Tomahawk 5/6) are incredibly fast “pipes,” but they are “dumb” pipes—they do not have the ALUs (Arithmetic Logic Units) required to sum tensors as they pass through the port.
The Math of SHARP v3 (Scalable Hierarchical Aggregation and Reduction Protocol)
While Ethernet is an excellent transport, it is a “passive” fabric. InfiniBand XDR is an “active” compute element.
The In-Network Advantage: In an All-Reduce operation (summing gradients), data typically traverses the fabric multiple times. With SHARP v3, the switch silicon performs the summation.
The Impact: In a 3-tier fat-tree topology, SHARP reduces the traffic on your spine links by 50%. By calculating the vector sums in the ASIC as packets pass through, you effectively double the bisection bandwidth for collective operations.
TCO Calculation: If a $100M training run is 30% communication-bound, a 2x faster collective operation via SHARP can shave 15% off the JCT. On a $100M project, that is $15M in saved compute time—far outweighing the 2x premium in switch hardware costs.
4. Protocol Efficiency: “Goodput” and Overhead
At 800Gbps, the percentage of the wire dedicated to headers becomes a multimillion-dollar TCO factor.
To analyze the choice between InfiniBand (NDR/XDR) and high-end Ethernet (Spectrum-X/Ultra Ethernet) we must look at the Net Present Value (NPV) of your GPU cluster. For a seasoned pro, the hardware cost is a distraction; the real metric is Goodput-per-Watt and Job Completion Time (JCT).
The Final Verdict
Choose InfiniBand XDR if you are building a Foundation Model cluster (>1,000 GPUs). The “Tax” you pay on hardware is actually “Insurance” against unpredictable JCT. The SHARP offloads and deterministic tail latency ensure that your $40k GPUs aren’t spending 40% of their life cycle waiting for the network.
Choose Ethernet (Spectrum-X / UEC) if you are building a Multi-tenant Inference Cloud. Ethernet’s strengths in multi-vendor support, standard management (SNMP/gRPC), and lower CapEx make it the winner for inference and “fine-tuning-as-a-service” where job synchronicity is less critical.
A high-level architectural comparison for a massive-scale training cluster
At this scale (approx. 2,048 nodes x 8 GPUs/node), we are dealing with over 32,000 fiber endpoints just for the compute fabric. The primary design constraint is achieving full bisection bandwidth with minimal tail latency.
Here is the comparative architecture.
Architecture A: InfiniBand (NDR/XDR) 3-Tier Fat-Tree
This topology is designed for maximum determinism. It relies on a Centralized Subnet Manager (SM) to calculate loop-free forwarding tables and utilizes SHARP v3 to offload collective arithmetic to the spine layers.
Assumptions:
Compute Node: 8x NVIDIA H100/B200 GPUs.
NIC: 8x ConnectX-7 (NDR 400G) or ConnectX-8 (XDR 800G) per node.
Switch Silicon: NVIDIA Quantum-2 (NDR) or Quantum-X800 (XDR). Assuming a standard 64-port radix at 400G for this diagram to demonstrate the scale.
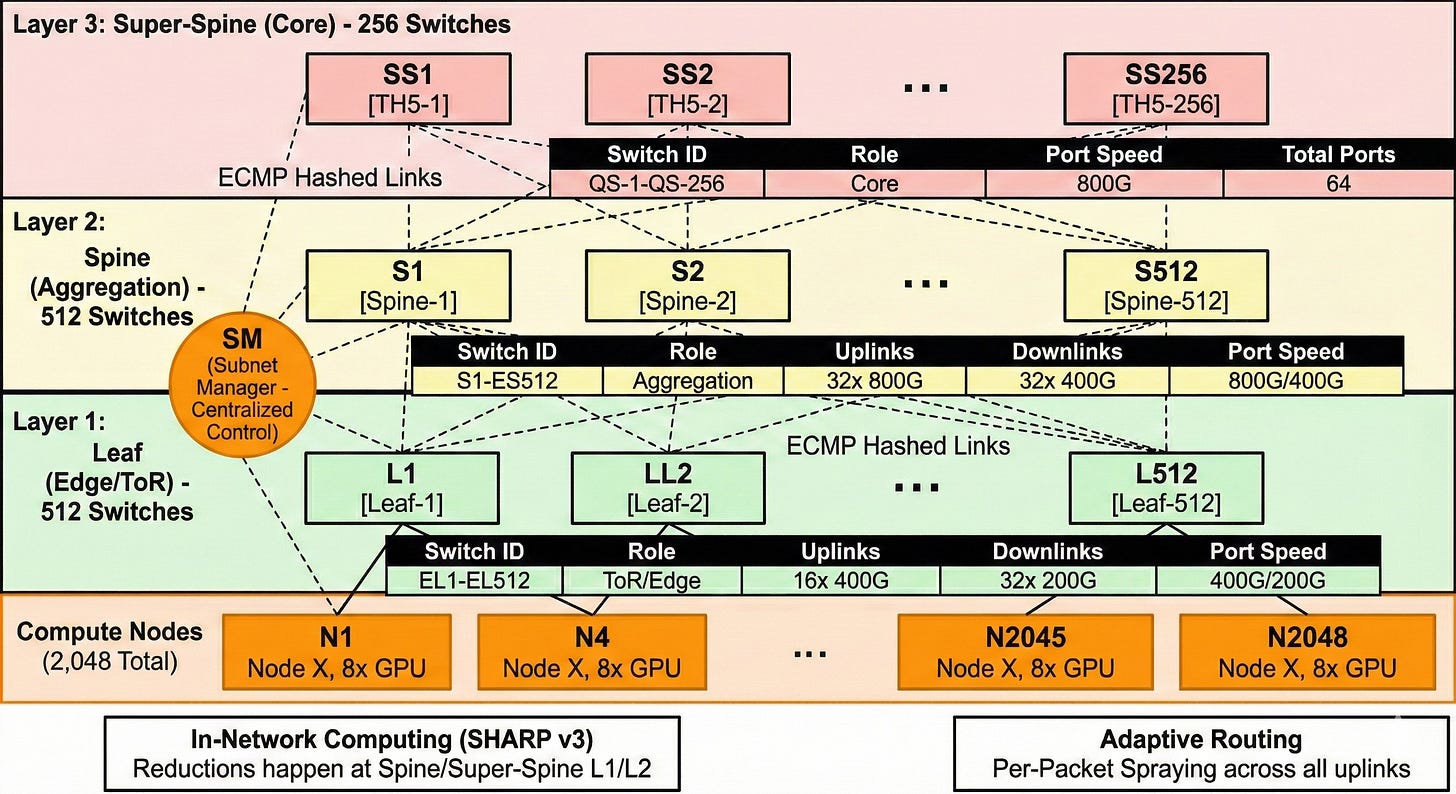
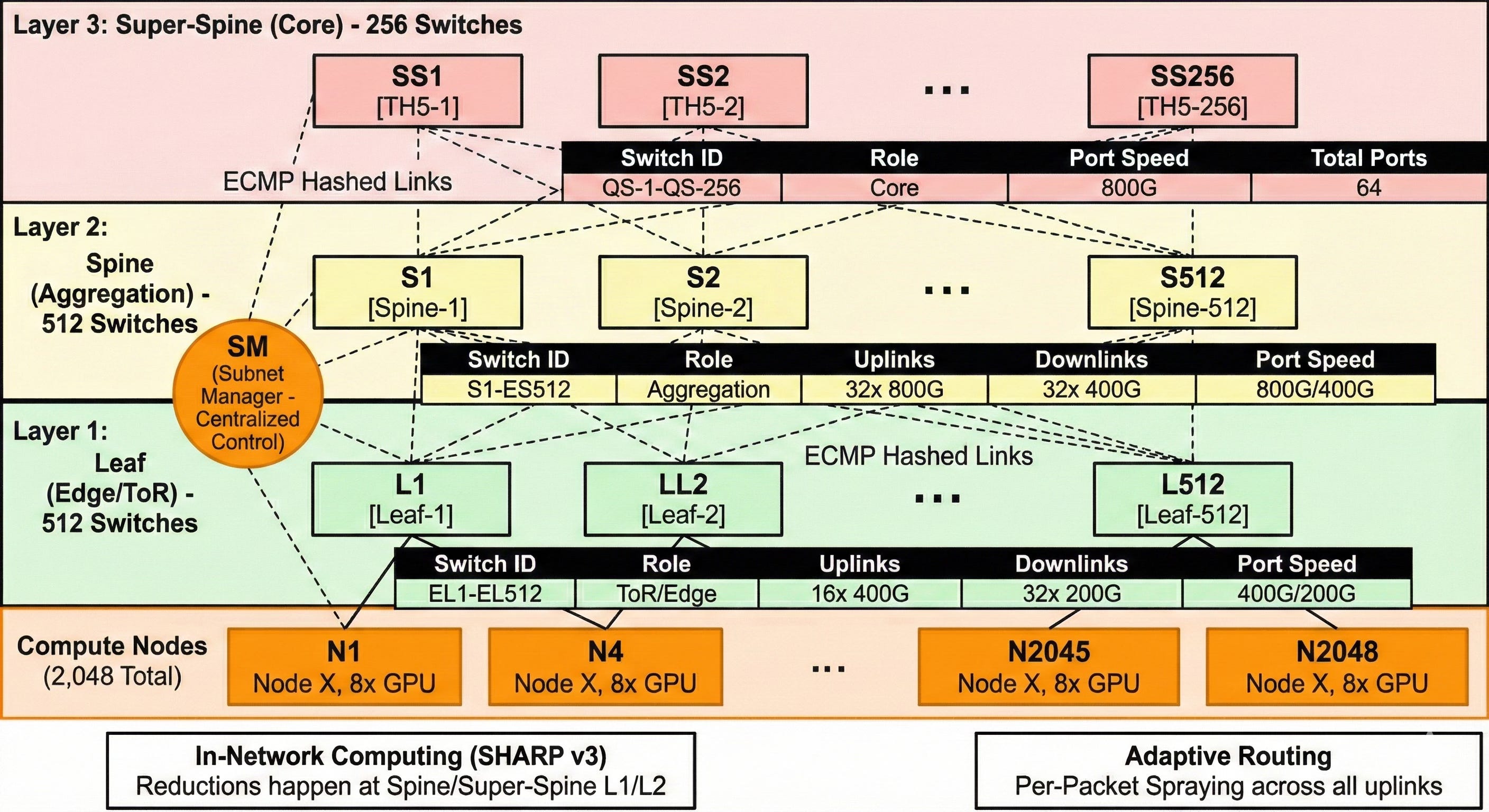
Key InfiniBand Architectural Characteristics for Pros:
Centralized Control (The Orange Circle): The Subnet Manager (SM) runs on dedicated appliances (usually redundant). It sees the entire 16k endpoint topology. It pre-calculates forwarding paths, ensuring no loops and deterministic recovery from link failures.
Active Fabric (SHARP): Data traveling up from Layer 1 to Layer 2/3 for an All-Reduce operation does not just pass through. The switches perform FP16/BF16 summations in-flight, reducing bandwidth pressure on the Super-Spine by ~50%.
Credit-Based Flow Control: Every single link shown uses hardware-level credits. A packet is not sent unless buffer space is guaranteed at the next hop. This is natively lossless without tuning.
Architecture B: Ethernet (RoCEv2/UEC) 3-Tier Clos
This topology relies on standard IP routing protocols (BGP) and statistical multiplexing (ECMP). It requires significant tuning of reactive congestion control mechanisms to handle AI traffic profiles.
Assumptions:
Compute Node: 8x GPUs.
NIC: 8x 400G/800G RoCEv2 (e.g., Broadcom Thor 2, NVIDIA BlueField-3) or UEC-compliant NICs.
Switch Silicon: Broadcom Tomahawk 5/6, Cisco Silicon One, or NVIDIA Spectrum-X. 64-port 400G radix assumed for comparison.
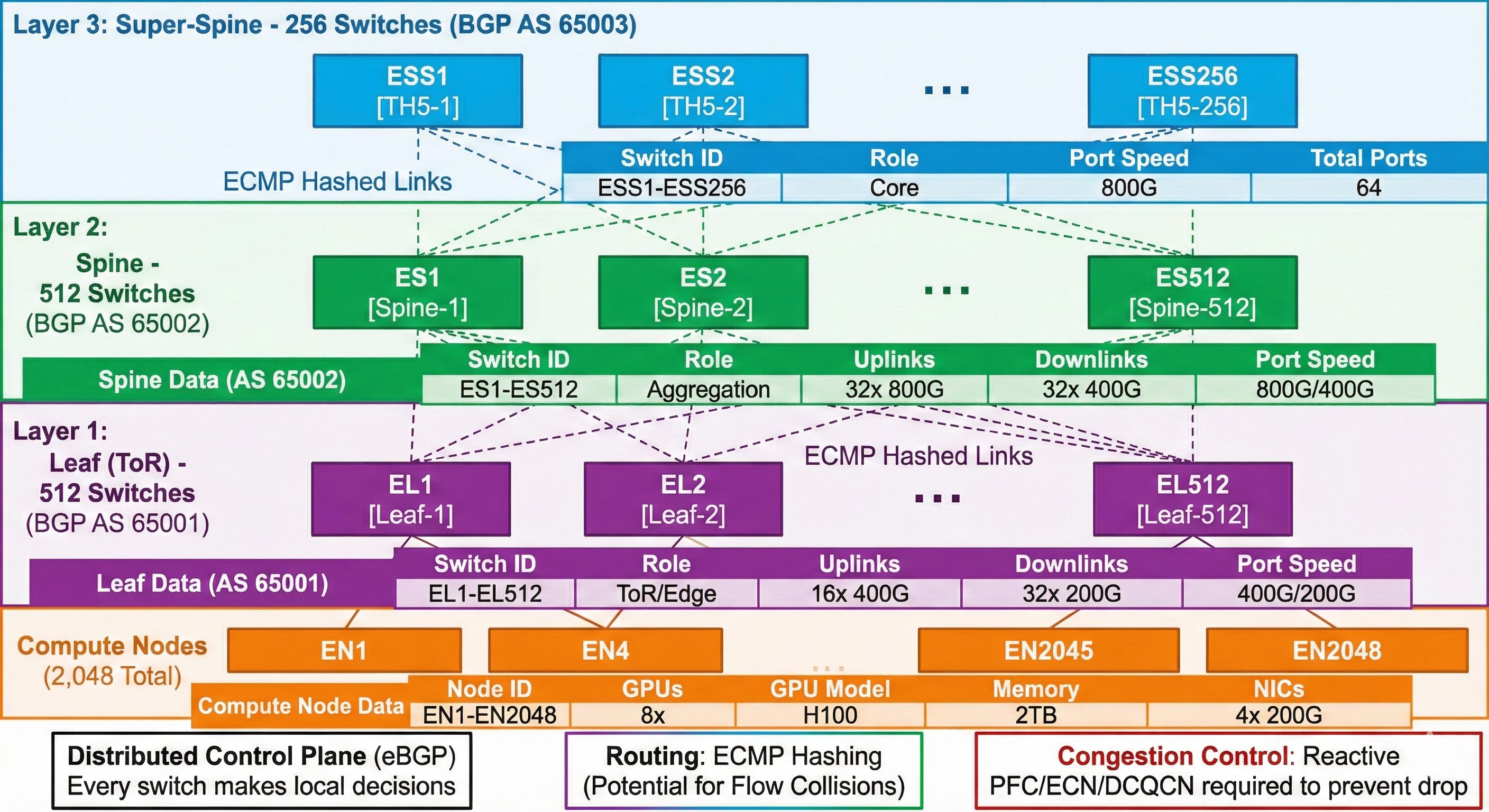
Key Ethernet Architectural Characteristics for Pros:
Distributed Control (Dashed Borders): There is no central brain. Every switch runs a BGP daemon. Convergence at 16k scale during a spine failure can take seconds, during which traffic may blackhole or loop, devastating synchronous training jobs.
Passive Fabric: The switches are high-speed forwarders only. Collective reductions (NCCL) are done entirely on the GPUs (at the bottom layer), requiring data to traverse the entire spine twice (up to peer, down to peer).
Reactive Flow Control (PFC/ECN): The fabric is inherently lossy. To support RoCEv2, Priority Flow Control (PFC) must be enabled. If a leaf switch buffer fills, it sends a PAUSE frame to the spine. At 16k scale, improperly tuned PFC leads to head-of-line blocking and “PFC storms” that can stall wide segments of the cluster.
ECMP Hashing (Dashed Lines): Traffic is balanced using 5-tuple hashing. In AI workloads with few, massive flows, hash collisions occur, leading to uneven link utilization (some links 100% full, others 40% empty) regardless of theoretical non-blocking design. (Note: UEC aims to fix this with packet spraying in late 2025, but requires new NICs/Switches).